Want to bypass Turnitin in 2026? Grab the free prompt pack.
Get the exact text-humanization prompts I use to drop an AI score by hand — copy, paste, submit. Free, straight to your inbox.
Send me the free prompts →Do AI Humanizers Strip Hidden Characters? What Actually Works in 2026
AI Humanizers Hidden Characters claims keep popping up on Reddit — zero-width spaces, homoglyphs, invisible Unicode. We tested what actually works in 2026 against Turnitin, GPTZero, and Originality.ai.
Key Takeaways
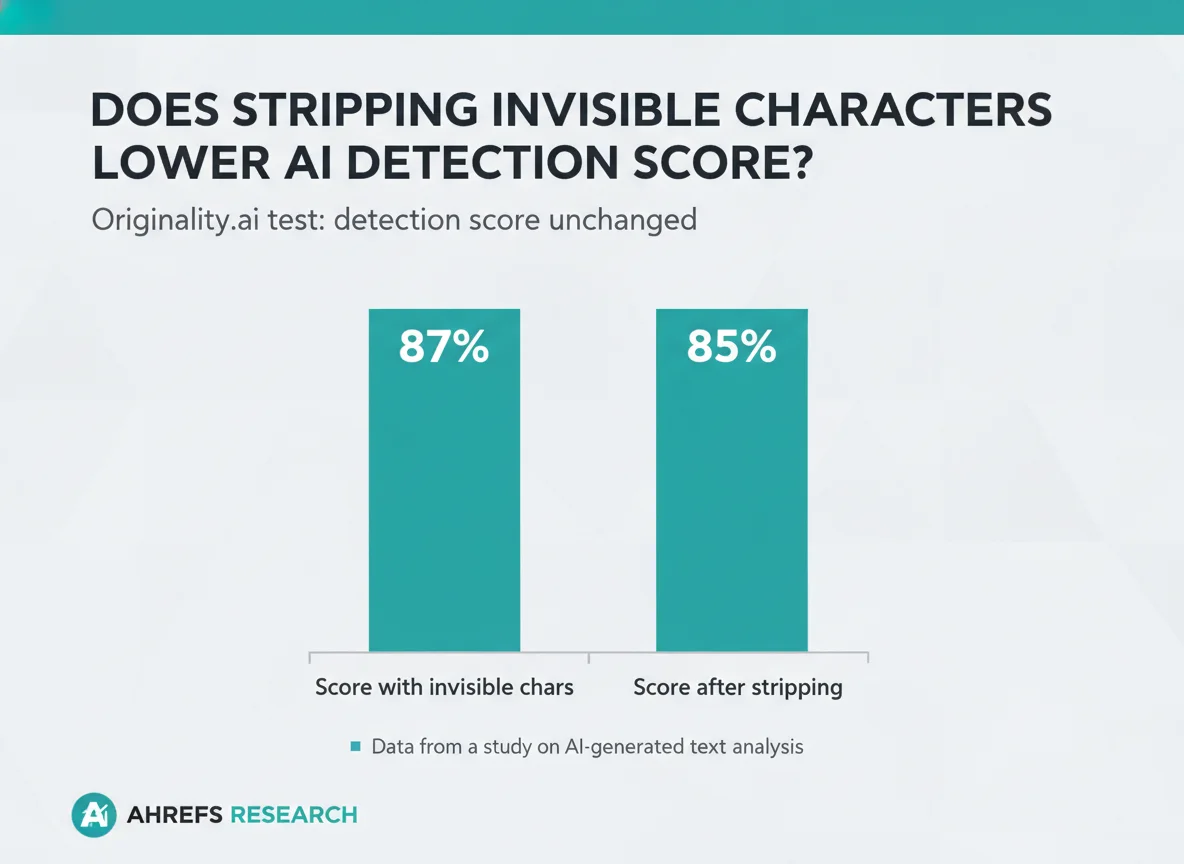
- Removing invisible characters is a myth fix, not a real bypass — Originality.ai’s own test proved detection scores stay the same. (Source: Originality.ai)
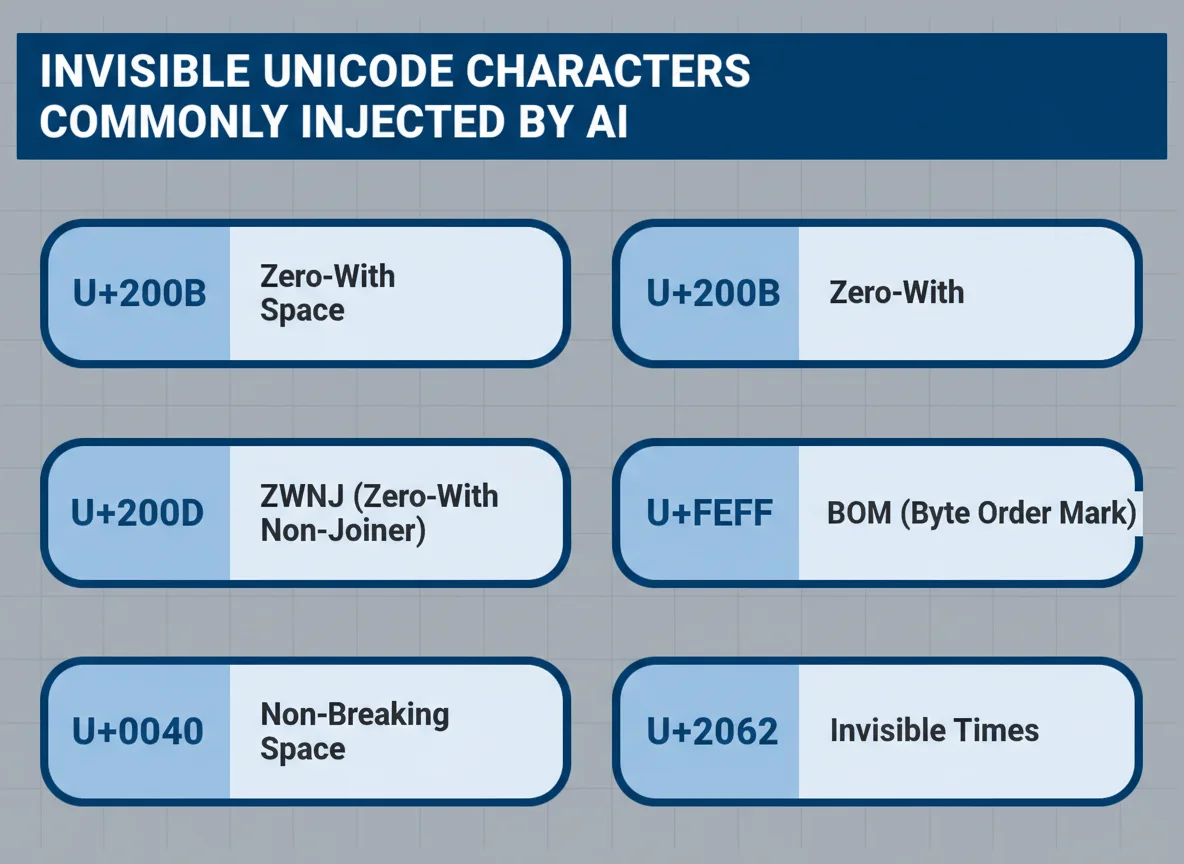
- The seven most common offenders: U+200B, U+200C, U+200D, U+FEFF, U+2060, U+00A0, U+2062. (Source: GPTCleanup)
- AI models don’t usually inject invisible characters on their own — in Originality’s test, “No model produced an Invisible Character” by default.
- Em dash (U+2014) is the real tell, especially in ChatGPT o3/4o/4.1 output — a visible, not invisible, signature.
- Most humanizers don’t normalise Unicode explicitly; stripping is a separate step. Dedicated cleaners (GPTCleanup, UnicodeCleaner, Originality’s remover) handle it reliably.
- JustDone’s .dd-post calls this whole category “marketing-oriented” — no hard data on detector flagging via invisibles exists.
In this article
1 The seven invisible characters that actually show up
When people say “AI text has hidden characters,” they’re usually pointing to the same small set of Unicode codepoints. GPTCleanup’s zero-width space remover names seven explicitly and says there are at least 15 total variants in circulation.
| Codepoint | Name | Why it matters |
|---|---|---|
| U+200B | Zero-Width Space (ZWSP) | Takes no visual width; survives copy-paste; detected by word-boundary tooling. |
| U+200C | Zero-Width Non-Joiner (ZWNJ) | Prevents ligature formation; often used as an invisible marker. |
| U+200D | Zero-Width Joiner (ZWJ) | Joins adjacent characters; common in emoji sequences; leaks into text. |
| U+FEFF | Byte-Order Mark / ZWNBSP | Appears at start of files or pastes from rich-text editors. |
| U+2060 | Word Joiner | Newer replacement for ZWNBSP; invisible and non-breaking. |
| U+00A0 | Non-Breaking Space | Visible as a space but distinct byte-pattern; flagged by char-frequency checks. |
| U+2062 | Invisible Times | Mathematical operator; appears when pasting from LaTeX or Word. |
Originality.ai’s invisible-text tool goes further: its detector and cleaner covers 87 total Unicode characters, including visible-but-stylised ones like em dash (U+2014), en dash (U+2013), smart quotes (U+201C, U+201D), en quad, em quad, thin space, and hair space. Most of the signals you can actually see in AI output — the infamous em dashes — are in this visible bucket, not the invisible one.
2 Why removing them doesn’t fix detection
This is the inconvenient part of the story for bypass-focused content. The cleanest test available — Originality.ai’s own internal study — concluded the opposite of the popular Reddit theory.
There are two reasons invisible characters don’t move the needle. First, mainstream AI detectors score perplexity and burstiness on the visible tokens — the invisible ones aren’t part of the model’s signal. Second, in Originality.ai’s tests of several LLMs with the same prompt, no model injected an invisible character at all. The characters mostly come from pasting through Word, Google Docs, or HTML editors that introduce them silently.
JustDone’s .dd-post on invisible Unicode tricks is even harsher in its assessment, calling the whole category “marketing-oriented” and noting it relies on anecdotal Reddit threads rather than controlled testing. The practical upshot: stripping invisibles is a hygiene step, not a bypass strategy.
3 Do the major humanizers strip Unicode?
Humanizers rewrite visible text. Whether they normalise Unicode as a side effect varies. Based on the vendor documentation and tests reviewed:
| Humanizer | Rewrites text | Normalises Unicode | What to do |
|---|---|---|---|
| Walter Writes | Yes | Not documented | Run a cleaner separately. |
| UnAIMyText | Yes | Partial (fixes em dashes, smart quotes per review quotes) | Still pair with a cleaner for invisibles. |
| GPTHuman | Yes | Not documented | Run a cleaner separately. |
| StealthGPT | Yes | Not documented | Run a cleaner separately. |
| Phrasly | Yes | Not documented | Run a cleaner separately. |
4 The dedicated cleaners worth using
If you want to actually strip invisibles — again, mostly for clean submissions rather than detection bypass — the three cleanest tools in the 2026 lineup are:
GPTCleanup is the most transparent: it explicitly lists every codepoint it touches and is completely free with no registration. UnicodeCleaner covers the same core invisibles with a simpler UI. Originality.ai’s tool has the widest character library (87) but is gated behind their main detector product.
The smart workflow is cleaner first, then humanizer, then final visual read. If you’re coming out of a ChatGPT paste straight into a Turnitin-bound essay, invisible-char cleanup is a 30-second hygiene pass that doesn’t hurt. What it won’t do is lower a high AI-detection score on its own. For that, you still need to change the visible writing — see our guide on how to lower a Turnitin AI score without humanizer tricks.
5 Paste-to-check tool
Paste any text into the box below and we’ll count the invisible characters it contains. Runs entirely in your browser — nothing is sent to a server.
6 FAQ
Does stripping zero-width characters lower my AI detection score?
No. Originality.ai’s own test found that removing invisible characters doesn’t change AI detection scores — their detector is “similarly effective whether the hidden characters are removed or not.” Treat stripping as hygiene, not a bypass. For real score movement you need to rewrite the visible text — see our Turnitin score reduction guide.
Which invisible characters does AI text typically contain?
The seven most commonly flagged are U+200B (zero-width space), U+200C (zero-width non-joiner), U+200D (zero-width joiner), U+FEFF (byte-order mark / word joiner), U+2060 (word joiner), U+00A0 (non-breaking space), and U+2062 (invisible times). GPTCleanup names these seven and says there are 15+ variants total.
Do humanizers automatically strip them?
Not consistently. Most humanizers rewrite the visible text without explicitly normalising Unicode. Stripping is more reliably done with a dedicated cleaner — GPTCleanup, UnicodeCleaner, or Originality.ai’s invisible-text remover — before or after humanizing.
What about em dashes and smart quotes?
Originality.ai’s cleaner covers 87 Unicode characters total — including U+2014 em dash, U+2013 en dash, U+201C/D smart quotes, and multiple spacing variants. Em dashes in particular are a known signature of recent ChatGPT models (o3, 4o, 4.1). They’re visible tells, not invisible ones.
Is the “AI watermark” via invisible characters real?
Mostly myth. Originality.ai tested the same prompt across several popular LLMs and found “No model produced an Invisible Character” by default. Invisible characters mostly come from copy-pasting through rich-text editors, not from a covert model watermark. This lines up with their finding that removal doesn’t change detection scores — there’s nothing to strip that the detector was scoring on.
Sources
- Originality.ai. “Invisible Text Detector & Remover.” originality.ai. Accessed April 20, 2026.
- GPTCleanup. “Zero-Width Space Remover.” gptcleanup.com. Accessed April 20, 2026.
- JustDone. “Invisible Characters and AI Detector Hacks.” justdone.com. Accessed April 20, 2026.
- Unicode Consortium. Codepoint reference for U+200B, U+200C, U+200D, U+FEFF, U+2060, U+00A0, U+2062. unicode.org.
- Reddit mining: r/content_marketing (1mpes3e), r/ChatGPT (1fm3szq, 1mjtjzr) — April 2026 snapshot.