
Stop getting flagged. Lower your AI score — for free.
40 manual tactics, 3 rewrite frameworks, 2 copy-paste prompts, and a 12-step false-flag defense playbook. No $20/month humanizer that fails on Turnitin anyway.
Get the Toolkit $7 →A good AI humanizer can make machine-written text sound more natural, but that does not mean it becomes invisible to modern AI detectors. In 2026, detectors (especially academic-focused ones like Turnitin) increasingly look beyond obvious “robotic tone” and into deeper statistical and stylistic signals, plus document context. That is why users often see a frustrating outcome: the humanized version reads better, but still gets flagged.
This guide breaks down how AI humanizers work under the hood, what detectors actually measure, and the most common reasons “humanized” text still trips AI detection.
What an AI humanizer actually does (in plain English)
Most AI humanizers are not magic “cloak” tools. They are rewriters that transform a draft by changing wording, rhythm, and structure while trying to preserve meaning.
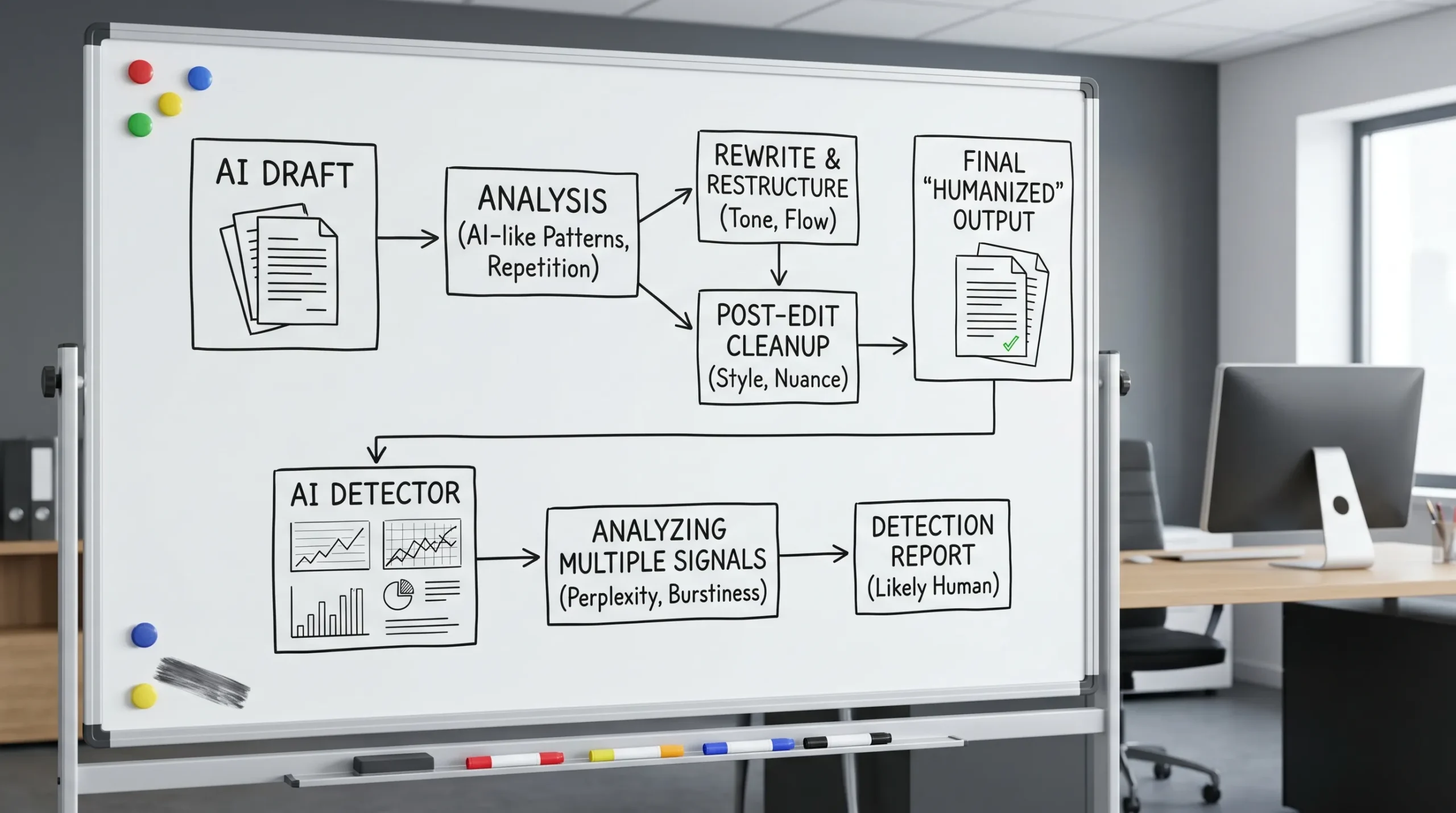
At a high level, a typical humanizer pipeline looks like this:
- Analysis: The tool estimates what parts look “AI-like” (often via heuristics such as repetitiveness, overly uniform sentence length, predictable transitions, and low variation in phrasing).
- Rewrite: It paraphrases, restructures, and adds stylistic variation.
- Post-processing: It cleans grammar, normalizes formatting, sometimes adds contractions, adjusts punctuation, and tries to improve flow.
- (Sometimes) verify: Some tools run the output through one or more detectors and iterate.
The most common humanizer techniques
Different tools brand these differently, but most rely on a mix of these tactics:
- Surface-level variation: swaps synonyms, changes phrasing, tweaks punctuation, breaks up long sentences, and adds contractions.
- Structural rewriting: reorders clauses, changes paragraph structure, merges or splits sentences, changes topic sentence placement.
- “Burstiness” injection: alternates short and long sentences, varies cadence, and adds occasional imperfect-but-human transitions.
- Style transfer: attempts to imitate a more personal voice (first-person framing, mild hedging, occasional asides).
- Constraint handling: tries to preserve names, numbers, citations, and formatting (this is where many humanizers still fail).
Done well, these changes often improve readability and reduce the “template” feel. But detectors are adapting to exactly these transformations.
Why detectors still flag humanized text
To understand false flags and stubborn flags, it helps to see AI detection as classification under uncertainty, not as a definitive “AI or not” test. Vendors rarely disclose full methods, but independent evaluations consistently show variability by text type, length, and writer profile.
A widely cited issue is bias against non-native English writers. For example, Stanford researchers reported high misclassification rates for non-native English writing in detector testing (see the Stanford HAI report described in Liang et al., 2023: Stanford HAI).
With that context, here are the main reasons detectors still flag text after humanization.
1. Detectors learn humanizer “fingerprints”
Once a humanizer becomes popular, its outputs become training data (directly or indirectly). Detectors can start to recognize:
- common rewrite patterns (certain synonym choices, repeated syntactic shapes)
- “too clean” paraphrasing that reduces natural idiosyncrasies
- unnatural uniformity introduced by a single rewrite model
This is why a tool might work well for a few months, then degrade after detector updates.
2. Humanizers often fix the wrong problem: tone, not authorship signals
Many people assume detectors only look for “robot tone.” In practice, detectors can also be sensitive to:
- overly consistent grammar and structure across long passages
- low variance in vocabulary difficulty
- generic claims without assignment-specific details
- a lack of personal “process residue” (small inconsistencies, evolving phrasing, genuine specificity)
A humanizer can polish tone while not adding the kinds of content that signals genuine authorship, like concrete examples, course-specific framing, or original reasoning steps.
3. Mixed authorship is inherently hard, and detectors often overreact
Real-world writing is often mixed:
- you write some parts
- AI drafts some parts
- you paraphrase
- Grammarly or another editor smooths everything
- a humanizer rewrites the whole document
This can create a “statistical patchwork” where sections differ in style distribution. Many detectors treat that inconsistency as suspicious, even when the human involvement is legitimate.
4. Over-humanizing can create new detectable artifacts
Aggressive rewriting can introduce patterns that are arguably more suspicious than the original:
- awkward synonym substitutions (“synonym salad”)
- slightly off collocations and unnatural phrasing frequency
- repetitive hedging (“arguably,” “notably,” “it is worth noting”) inserted too regularly
- paragraph rhythm that looks engineered rather than organic
Some detectors flag this as “paraphrased AI” or “AI with heavy editing,” even if the output reads fine at a glance.
5. Detectors use context and formatting signals, not just sentences
Academic detectors can incorporate document-level cues such as:
- long stretches of uniformly formatted prose
- citation and reference patterns
- repeated template phrasing across submissions
- unusually consistent voice across sections that typically vary (intro vs discussion vs limitations)
If a humanizer normalizes everything into a single “smooth” register, it can unintentionally increase uniformity.
6. Short text is unstable for both humanizers and detectors
For very short passages (a paragraph, a discussion post, a reflection), small edits can swing detection scores wildly because the classifier has less evidence. In those cases:
- a humanizer may not have enough room to introduce meaningful variation
- a detector may overfit to a few phrases or transitions
7. The “arms race” logic favors false positives in high-stakes settings
In classrooms, publishing, and compliance workflows, vendors often tune systems to reduce missed AI usage. That can raise false positives.
A useful analogy is document fraud detection: in invoice and receipt workflows, organizations accept some manual review burden to prevent costly fraud. Tools like invoice and receipt fraud detection software focus on forensic signals (pixel-level manipulation, metadata, mathematical irregularities) rather than only surface-level appearance. AI text detection has a similar dynamic: as rewriting gets better, detectors widen the set of signals they consider, which can increase flags on legitimate work.
Humanizer tactics vs detector counter-signals (and where it breaks)
The table below summarizes the cat-and-mouse dynamic in a practical way.
| Humanizer technique | What it tries to change | What detectors can still look at | Common failure mode |
|---|---|---|---|
| Synonym swaps and paraphrasing | Predictable wording | Embedding-level similarity, paraphrase signatures | “Synonym salad,” unnatural collocations |
| Sentence splitting/merging | Rhythm and cadence | Document-level uniformity, syntactic patterns | Cadence becomes “engineered” |
| Transition variation | Template-like flow | Discourse consistency and argument specificity | Still generic, still low-specificity |
| Style transfer (more personal voice) | Human-like tone | Stylometry consistency with author’s other work | Voice mismatch vs past writing |
| Aggressive restructuring | Break AI-like structure | Coherence and factual stability | Meaning drift, citation damage |
| Multi-pass rewrite + retest | Optimize for a detector | Cross-detector disagreement | Improves one score, worsens another |
Why “passing one detector” does not generalize
A common misconception is that if a humanized draft passes Detector A, it is “safe.” In reality:
- Detectors disagree because they use different training data, thresholds, preprocessing, and feature sets.
- Upload context matters in some systems (formatting, length, and academic conventions can shift results).
- Updates are frequent, so yesterday’s pass is not tomorrow’s pass.
That is why chasing a single low score can become a loop with diminishing returns.
Stop getting flagged. Lower your AI score — for free.
40 manual tactics, 3 rewrite frameworks, 2 copy-paste prompts, and a 12-step false-flag defense playbook. No $20/month humanizer that fails on Turnitin anyway.
Get the Toolkit $7 →What to do instead: make writing more defensibly yours
If you are humanizing text for legitimate reasons (clarity, ESL support, tone improvement, reducing robotic phrasing), aim for authenticity and defensibility, not “undetectability.” Practically, that means:
Add specificity that a rewriter cannot invent safely
Detectors (and instructors) respond well to details that are hard to fake:
- assignment-specific constraints (prompt terms, required sources, rubric language)
- concrete examples from your readings, lab, dataset, or case
- your own reasoning chain (why you chose one interpretation, what you ruled out)
This also improves the actual quality of the work.
Use a light rewrite, then do a human pass
Humanizers are strongest as a first pass. Your second pass should:
- restore any lost nuance
- add natural variation (not random variation)
- check citations, numbers, names, and quoted material
Read it aloud. If it sounds like a well-edited brochure rather than a person thinking, add more real reasoning and less polish.
Keep proof of process (especially for Turnitin disputes)
If a detector flags your work, process evidence is often more persuasive than arguing about percentages:
- drafts and outlines
- Google Docs or Word version history
- source notes, highlights, Zotero libraries
- a short timeline of how the draft evolved
Where Detection Drama fits (without overpromising)
Detection Drama focuses on free methods and tools to help you understand AI detection behavior, review why text gets flagged, and rewrite AI-generated content into more natural language. If you are testing edits before submitting, the site also provides instant access tools (no email required) and a directory of resources for AI authenticity analysis.
Just keep the core reality in mind: no tool can guarantee a permanent bypass against evolving detectors, especially in high-stakes academic workflows.
Frequently Asked Questions
Do AI humanizers guarantee you will bypass Turnitin? No. Humanizers can reduce risk in some cases, but Turnitin and other detectors update frequently, and results vary by text type, length, and writing style.
Why does humanized text still get flagged even when it sounds human? Because detectors can rely on deeper statistical patterns, document-level uniformity, paraphrase fingerprints, and context signals beyond “robot tone.”
Can heavy editing tools like grammar checkers contribute to AI flags? They can. Over-smoothing, uniform tone, and consistent sentence structure can remove natural variation, which may make text look more machine-like to some classifiers.
Is a detector flag proof that someone used AI? No. A flag is typically a probabilistic indicator, and independent research has shown false positives and bias, especially for non-native English writing.
What is the safest way to reduce AI-detection risk ethically? Build a draft with real specificity and original reasoning, keep version history, and revise manually for clarity instead of optimizing for a score.
Try a safer “revise and verify” workflow
If you are revising AI-assisted drafts, focus on two outcomes: (1) the writing reads like you, and (2) you can prove your process if questioned. You can use Detection Drama’s free humanizer tool and AI detection bypass guides as part of a pre-submission check, then do a human editing pass that adds assignment-specific detail and preserves factual accuracy.
Stop getting flagged. Lower your AI score — for free.
40 manual tactics, 3 rewrite frameworks, 2 copy-paste prompts, and a 12-step false-flag defense playbook. No $20/month humanizer that fails on Turnitin anyway.
Get the Toolkit $7 →