
Copyleaks is one of the most commonly referenced “AI content detector” brands in 2026, so it’s natural to ask the question students, editors, and compliance teams actually care about: can it detect AI reliably enough to make decisions?
The most accurate answer is nuanced:
- Copyleaks can be useful as a screening signal, especially for longer, generic, high fluency text that resembles common LLM outputs.
- Copyleaks is not reliable as standalone proof of AI authorship, particularly in high stakes settings (academics, HR, legal, publishing). Like all AI detectors, it faces fundamental limits that haven’t disappeared in 2026.
Below is what Copyleaks can and cannot tell you, why false positives still happen, and how to interpret results without overreacting.
What Copyleaks is actually trying to measure
AI detectors are often described as “catching AI,” but that framing hides the core challenge. Copyleaks is not reading your browser history or accessing the model you used. It’s evaluating text and estimating something closer to:
- Does this text look statistically similar to text commonly produced by LLMs?
Copyleaks’ product pages describe an AI detector designed to identify AI generated content across common use cases (education, publishing, business). You can review their positioning here: Copyleaks AI Content Detector.
What matters for reliability is that this is pattern inference, not provenance. Even a “high confidence” output is still a probability judgment based on patterns that can overlap with legitimate human writing.
What “reliably” should mean in 2026 (and why most people define it wrong)
Most arguments about AI detection skip the real question: reliable for what?
A detector can be “good enough” for one workflow and dangerously misleading for another.
Reliability in practice depends on four things
- False positives (human text flagged as AI): the most harmful failure in schools and HR.
- False negatives (AI text not flagged): the most common frustration for instructors and editors.
- Calibration: whether a score reflects real-world odds, or just a model’s internal confidence.
- Base rates: how common AI use is in your specific context.
Base rates matter more than most people realize. Even a detector with a low false positive rate can cause lots of wrongful flags if the true rate of AI use is low.
A key 2026 reality: the science is still not “court-grade”
OpenAI itself discontinued its AI Text Classifier in 2023, citing low accuracy, especially outside English and on short text. That’s still instructive in 2026 because it reflects a broader truth about the problem, not a single vendor’s implementation. See: OpenAI’s notice about retiring the AI classifier.
Copyleaks and other vendors have improved since then, but the underlying difficulty remains: you can’t reliably prove authorship from text alone.
Real limits of Copyleaks AI detection in 2026
Copyleaks can be “right” often and still be unreliable when consequences are high, because the failure modes are predictable and frequent.
1) Short text is still a weak signal
Short passages do not provide enough statistical evidence for stable classification. This is true across detectors.
In practice, short text gets flagged (or cleared) based on fragile signals like:
- unusually consistent sentence structure
- low variation in word choice
- high polish and low “noise”
That’s not unique to AI. It’s also how strong student writers, professional editors, and non-native writers can sound.
2) Mixed authorship breaks the binary question
Most modern writing is mixed:
- outline by a human
- draft with AI
- heavy human revision
- grammar pass with a tool
Detectors often behave as if authorship is binary (“AI” vs “human”). In real workflows, it’s a spectrum.
So even when Copyleaks is directionally correct (some AI assistance occurred), its output may be misused as “proof the person didn’t write it.”
3) Paraphrasing and editing can change scores without changing meaning
A major limitation of all AI content detectors is that form matters more than meaning.
Two texts can communicate the same ideas, cite the same sources, and make the same argument, yet get very different detector outputs due to:
- sentence rhythm and variation
- specificity and “lived” detail
- distribution of rare versus common phrases
This is why detector scores often swing after ordinary revision. That does not automatically imply someone is “evading” detection. It’s a property of how classifiers work.
4) Non-native English and “academic safe style” can be over-flagged
Bias is not a theoretical concern, it’s documented.
Stanford HAI researchers found dramatic false positive rates on non-native English samples in widely used detectors (for example, a frequently cited result reported 61% of TOEFL essays were flagged as AI in their testing). This type of issue affects the whole category of detectors, not just one product. A broader discussion and sources are summarized in our research roundup: AI detection bias against ESL students.
If your environment includes many multilingual writers, Copyleaks results should be treated as especially non-decisive.
5) Model drift and “detector lag” never ends
By 2026, writers use many models (different versions, fine-tunes, open weights, and domain-specific systems). Detectors must constantly update to keep up.
That creates a persistent gap:
- new writing models appear
- usage patterns shift
- detectors retrain later
So “reliable last year” does not guarantee “reliable this semester.”
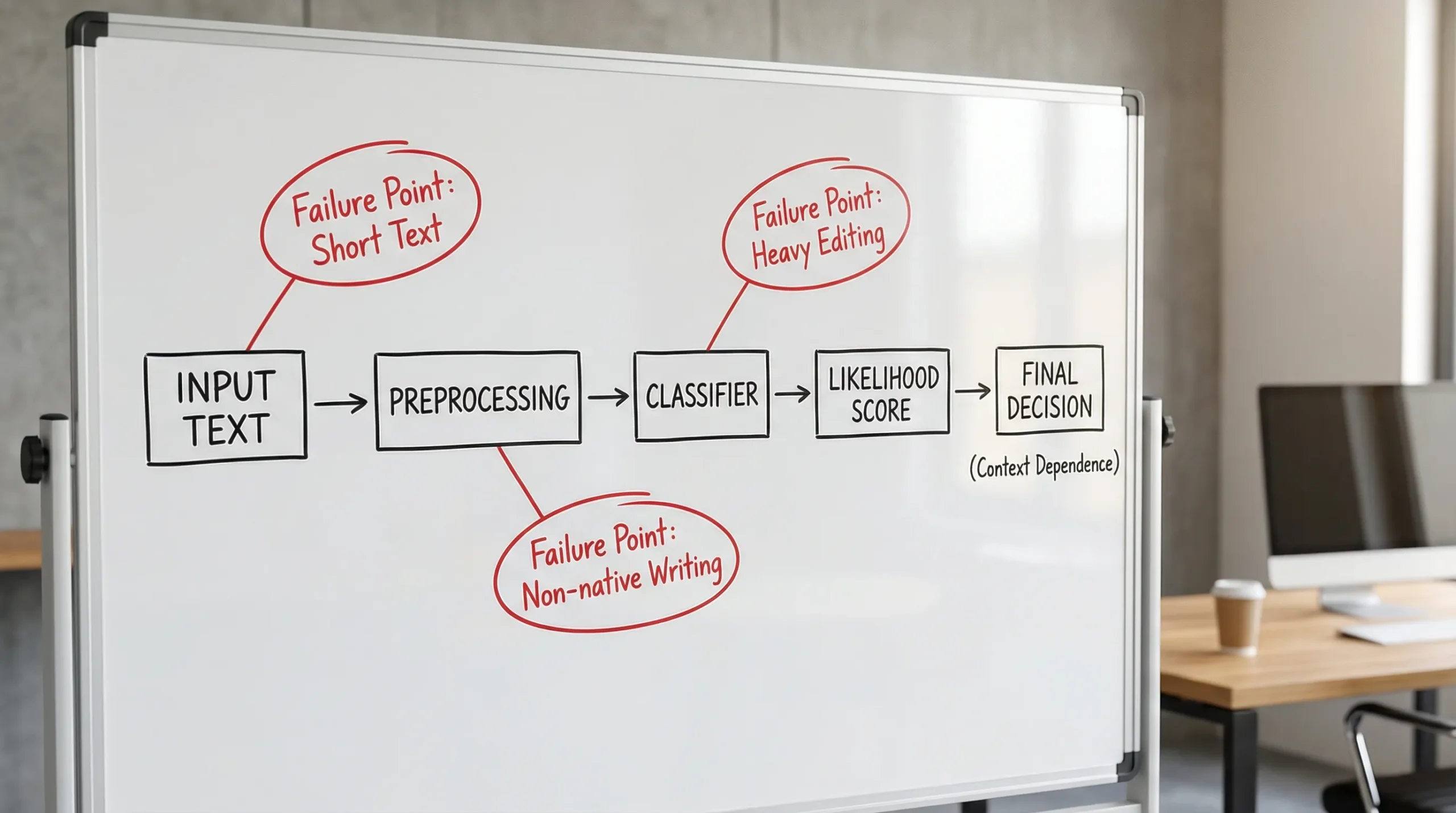
Common situations where Copyleaks results are most likely to mislead
The table below is not a claim about Copyleaks internals, it’s a practical summary of widely observed detector failure modes that show up across tools in 2026.
| Scenario | Why an AI detector may misfire | Safer interpretation |
|---|---|---|
| Very short answers (discussion posts, reflections) | Not enough signal, scores swing easily | Treat as “insufficient evidence,” request process proof instead |
| Highly polished, template-like academic writing | Academic structure can resemble “model” outputs | Look for assignment-specific reasoning, drafts, and citations |
| ESL writing | Detector bias and distribution differences | Use human review and authorship evidence, avoid automated penalties |
| Text heavily edited with grammar tools | Over-smoothed prose can look machine-generated | Ask for version history and earlier drafts |
| Mixed AI + human writing | Binary labels oversimplify | Evaluate disclosure rules, intent, and contribution, not just a score |
| Technical or citation-dense writing | Formatting, terminology, and quotations can confuse models | Separate quoted material, assess sections, and use domain review |
How to interpret a Copyleaks AI score without overreacting
If Copyleaks returns a strong “AI likely” result, the most defensible approach is to treat it like a smoke alarm, not a fingerprint.
Use Copyleaks as triage, not a verdict
A practical policy many teams adopt:
- Low signal: no action.
- Medium signal: manual review for specificity, source use, and coherence.
- High signal: request authorship evidence and have a structured conversation.
Copyleaks can help you decide where to spend attention, but it should not be the sole basis for accusations.
Ask for evidence that detectors cannot fake
If you are an instructor, editor, or manager, the strongest “reality checks” are process artifacts, not detector outputs:
- Google Docs or Word version history
- outlines, notes, and source annotations
- drafts showing development over time
- saved research links and reading notes
- a short live explanation of reasoning (oral defense)
If you’re a student who got flagged, this playbook helps you respond quickly and calmly: Accused of AI use: what to do in the next 24 hours.
When Copyleaks can be genuinely useful in 2026
Copyleaks is most useful when your goal is operational, not punitive.
Examples:
- Publishing and content operations: flagging suspiciously generic submissions for closer editing.
- SEO and brand teams: finding pages that read “mass-produced” and need stronger voice, examples, and originality.
- Compliance: identifying content that may have been generated without disclosure, so it can be reviewed for accuracy and sourcing.
In all these workflows, the next step is not “punish,” it’s “review and improve.”
When Copyleaks should not be used to make the call
Copyleaks (and any detector) is a poor fit when:
- the stakes are disciplinary or legal
- the text is short
- the writer is ESL or uses non-standard dialects
- the content is heavily edited by tools
- you cannot obtain process evidence
If your policy requires a yes or no answer from a detector, the policy is the fragile part.
A better 2026 workflow: corroborate, then improve the writing
If you’re trying to understand whether text “looks AI,” a more reliable approach is corroboration, not faith in one score.
- Compare results across more than one detector (they disagree often, and that disagreement is informative).
- Review the highlighted or suspicious sections for generic claims, thin evidence, and repetitive structure.
- If the writing must be clearly human-authored, focus on specificity, reasoning steps, and original examples.
If you need a fast way to analyze and revise text that keeps getting flagged, Detection Drama provides instant, no-email tools and guides focused on authenticity analysis and human-like rewriting, especially for high-stakes detectors like Turnitin. You can start from the homepage and tool directory here: DetectionDrama.com.

Bottom line: can Copyleaks detect AI reliably in 2026?
Copyleaks can detect AI-like patterns often enough to be useful as a screening tool. But it cannot reliably prove AI authorship, and the same well-known limits affecting the entire detector category still apply in 2026: short text instability, mixed authorship, paraphrase sensitivity, model drift, and documented bias risks.
If you’re making high-stakes decisions, treat Copyleaks as one input among several, prioritize process evidence, and use human review for the final call.