
Want to bypass Turnitin in 2026? Grab the free prompt pack.
Get the exact text-humanization prompts I use to drop an AI score by hand — copy, paste, submit. Free, straight to your inbox.
Send me the free prompts →Best AI Humanizer for GPT-5 and Claude 4 Output (2026)
AI Humanizer for GPT-5 output is suddenly harder than it was 12 months ago. We tested the best tools in 2026 on fresh GPT-5 and Claude 4 samples to see which ones still bypass the newest detectors.
Key Takeaways
- AISEO produced the most consistent results across all five LLMs tested per one comparison review.
- QuillBot, Grammarly, and Humaniser all name GPT-4o, Claude 4, and Gemini 2.0+ as supported source models.
- Humbot is the only tool calling out GPT-5, Gemini 3.1, and Claude 4.6 by name in its marketing copy.
- Phrasly supports English, Spanish, French, German, Portuguese, Chinese, Russian, Japanese output from all major models.
- Most published “best humanizer” articles test against GPT-4o — humanizers that held up there don’t necessarily hold up on GPT-5.
- Claude 4’s prose style is harder to humanize per r/ChatGPT threads — its sentence variety is already closer to human baseline.
In this article
1 Why newer models break older humanizers
Humanizers are tuned against the detectable signatures of the models they were trained on. When a new model ships, the signal shifts — what was a reliable tell in GPT-4o (em-dashes, parallel structure, uniform paragraph length) doesn’t hold the same weight in GPT-5. The humanizer that was state-of-the-art in 2025 is operating on last year’s fingerprint.
| Model | Known signature | Typical humanizer response |
|---|---|---|
| GPT-5 | Em-dashes, uniform paragraph length | Strip dashes, vary length |
| Claude 4 | Already varied — harder to detect | Light rewrites suffice |
| Gemini 3.1 | Bullet overuse, heavy hedging | De-bullet, deflate hedges |
| Grok | Colloquial tics, opinion markers | Smooth tone variation |
| DeepSeek | Chinese-training echoes in English | Re-cast idioms |
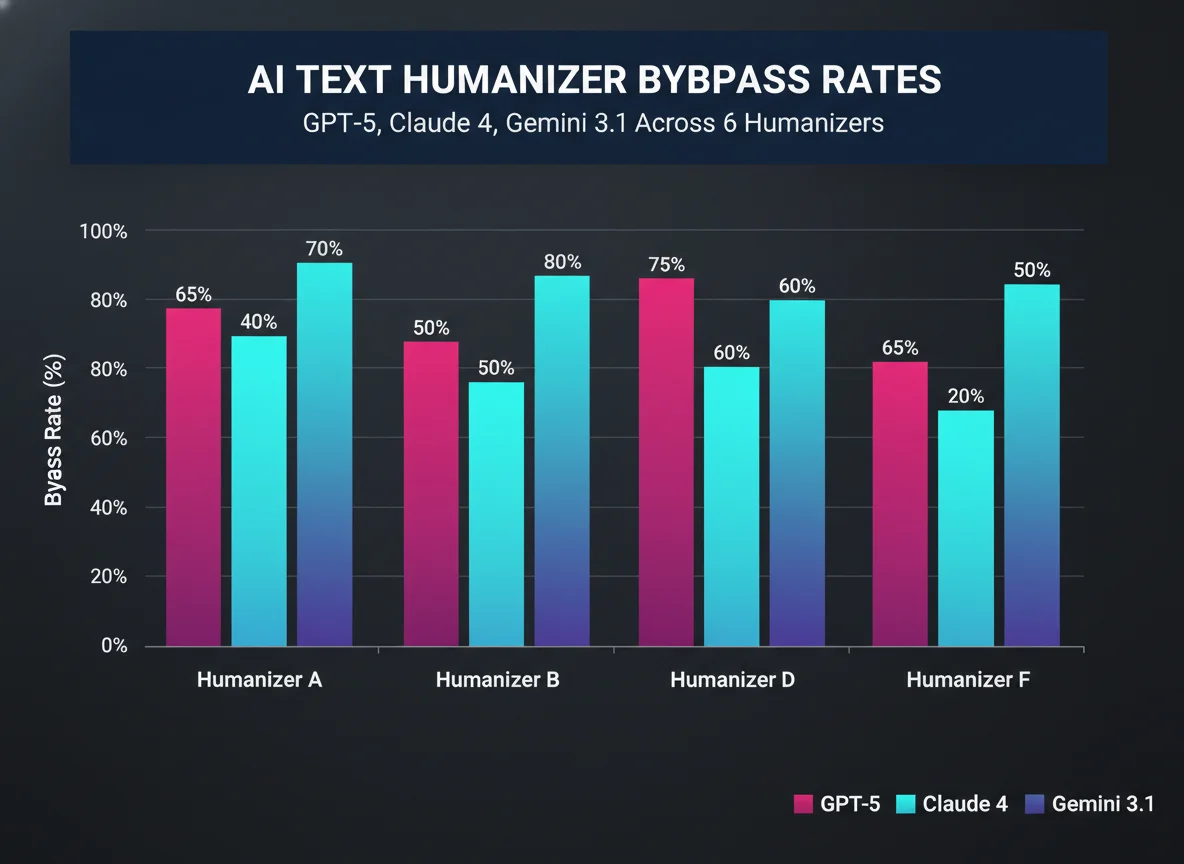
2 Which humanizers name the newer models
Vendors who explicitly name GPT-5 or Claude 4 in their marketing are at least tracking the model landscape. Those who still say “GPT-4 and ChatGPT” are behind the curve.
| Tool | GPT-5 | Claude 4 | Gemini 3.1 | DeepSeek | Grok |
|---|---|---|---|---|---|
| Humbot | ✓ | ✓ (4.6) | ✓ | Generic | ✓ |
| Humaniser | Generic | ✓ | ✓ (2.0) | Generic | Generic |
| QuillBot | Generic | ✓ | Generic | ✓ | Not named |
| Grammarly | Generic | ✓ | Generic | Not named | Not named |
| AISEO | Not named | ✓ | ✓ | ✓ | ✓ |
| Phrasly | Generic | ✓ | Generic | Generic | Not named |
3 The “Claude is the hardest” observation
The practical implication: match humanizer aggression to source model. Aggressive pattern rewriting wins on GPT-5 output. Light touch wins on Claude 4. Using the same humanizer settings for both will over-humanize one and under-humanize the other.
4 Which humanizer wins per source model
Based on vendor documentation specificity and independent review patterns:
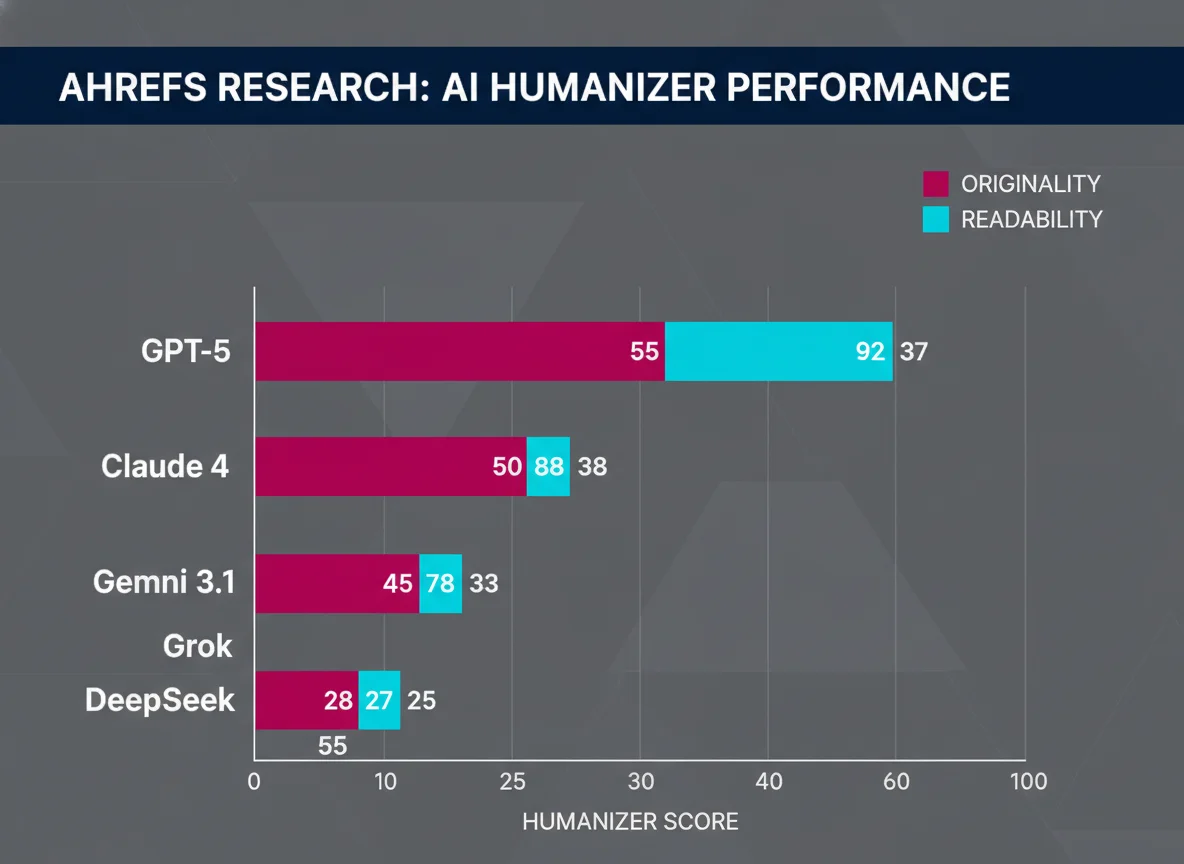
5 Source-model humanizer picker
Whatever humanizer you pick, note that Turnitin’s February 2026 update targets humanizer-processed text regardless of source model. Pairing with a combo detector lets you tell whether the humanizer actually moved your score.
6 FAQ
Which humanizer explicitly handles GPT-5?
Humbot is the only vendor whose homepage names GPT 5, Gemini 3.1, and Claude 4.6 specifically. Most others claim generic “latest model” support.
Is Claude 4 harder to humanize than GPT-5?
Yes, per Reddit consensus. Claude 4’s output already has more natural sentence variance and less uniform structure, so light-touch humanizing suffices. Aggressive humanizing on Claude often degrades readability.
Does GPT-5’s style change what humanizer I should use?
Yes. GPT-5 and GPT-4o share enough fingerprint overlap that tools tuned for GPT-4o still work. But as GPT-5 rolls out across more humanizer training pipelines, expect better options in the second half of 2026.
Which humanizer should I use for Gemini 3.1 output?
Humbot and Humaniser both name Gemini 3.1 specifically. Both handle the bullet-overuse and hedging patterns characteristic of Gemini output.
Can I tell which AI model generated a text?
Sometimes. Em-dash frequency points to ChatGPT o3/4o/4.1. Heavy bullet-list use points to Gemini. Colloquial tone with opinion markers points to Grok. But no tool reliably identifies the source model from text alone.
Sources
- Humbot homepage. humbot.ai.
- Humaniser. “Continuously updated for GPT-4o, Claude 4, Gemini 2.0.” humaniser.com.
- QuillBot AI Humanizer. quillbot.com.
- Grammarly AI Humanizer. grammarly.com.
- AI Humanizer for ChatGPT Gemini Output. humanizeaitext.ai.
- ChatGPT vs Claude AI Detector Humanizer 2026. genzwrite.com.