
AI Detection False Positive Rates: Complete Data by Tool (2026)
Key Takeaways
- 61.3% false positive rate for Chinese/TOEFL essays vs. 5.1% for US students — a 12× disparity (Stanford, 2023)
- Turnitin claims <1% FPR but its own CPO admitted 4%; a Washington Post study found 50% in one test
- ZeroGPT’s FPR in a large 37,874-essay benchmark: 26.4% — roughly 1 in 4 human texts wrongly flagged
- At 1% FPR, 223,500 US first-year essays would be wrongly flagged annually
- Top tools drop from 96–98% precision on clean AI text to 60–70% on humanized or edited content
- Remediating ESL bias through vocabulary enhancement reduced FPR by 49.7% (from 61.3% to 11.6%)
Table of Contents
- What Is a False Positive in AI Detection?
- False Positive Rates by Tool: Vendor Claims vs. Reality
- The ESL Bias Crisis: 61.3% vs. 5.1%
- Scale of the Problem: How Many Students Are Affected?
- Why Detectors Generate False Positives
- False Positive Impact Calculator
- What Reduces False Positive Rates?
- Methodology
- FAQ
- Sources & References
What Is a False Positive in AI Detection?
The stakes are asymmetric: a false negative (missed AI text) means one assignment passes undetected. A false positive means a real student faces an academic misconduct accusation with potentially career-ending consequences. Yet most university AI detection spending decisions focus almost exclusively on detection rates and rarely on false positive benchmarks.
Two metrics define detection reliability: the false positive rate (FPR) — the percentage of human-written texts incorrectly classified as AI — and the false negative rate (FNR) — the percentage of AI-written texts missed by the detector. This article focuses on FPR data, which is systematically under-reported by vendors and increasingly studied independently.
When tools like Turnitin or GPTZero process submissions, they assign probability scores, not definitive verdicts. But at the institutional level — where a single platform processes hundreds of thousands of submissions per semester — even a 1% error rate compounds into a systematic injustice.
False Positive Rates by Tool: Vendor Claims vs. Reality
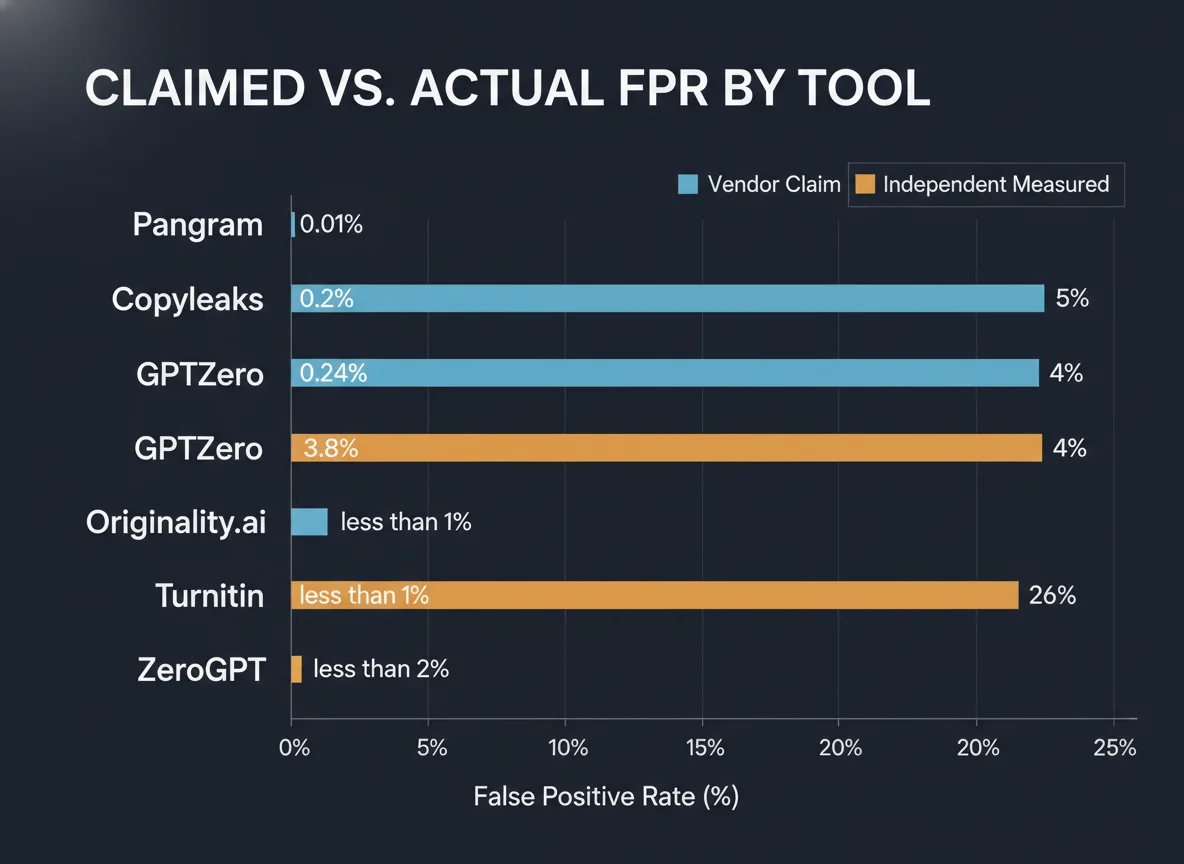
| Tool | Vendor Claimed FPR | Independent Measured FPR | Risk Level | Notes |
|---|---|---|---|---|
| Pangram | ~0.01% | ~0.01% | LOW | Consistent in lab tests; not widely adopted in academia |
| Copyleaks | 0.2% | ~5% (content-dependent) | MODERATE | Claims “industry’s lowest” FPR; independent results vary 25× |
| GPTZero | 0.24% | 1–18% (genre-dependent) | MODERATE | Higher on ESL writing (~19%) and creative genres |
| Originality.ai | 3.8% | 3.8–5% | MODERATE | One of the most transparent vendors; figures are plausible |
| Turnitin | <1% | 4–50% (source-dependent) | HIGH | CPO admitted 4%; Washington Post: 50% in one test; 98% accuracy claim is from controlled internal samples |
| ZeroGPT | <2% | 16–26.4% | HIGH | 26.4% in 37,874-essay benchmark; 1 in 6 human texts flagged per Pangram Labs test |
| Sapling / Writer | Not published | 28%+ | HIGH | Extremely high variance; not suitable for academic integrity decisions |
The wide variation in “independent” results also reflects the lack of standardised test corpora. Turnitin and GPTZero use different model architectures and are tested on different writing samples across studies. Until a neutral third-party benchmark using a common, demographically representative dataset is published, these numbers should be treated as order-of-magnitude indicators, not precise rankings.
The ESL Bias Crisis: 61.3% vs. 5.1%
The study, published in Patterns on July 14, 2023, evaluated 91 TOEFL essays from a Chinese student forum alongside 88 US eighth-grade essays from the Hewlett Foundation ASAP dataset. All seven detectors — including GPTZero, ZeroGPT, and Writer — were “near-perfect” on the US essays but collectively flagged the majority of the TOEFL essays.
The disparity is mechanistic, not conspiratorial. Most AI detectors measure perplexity — a statistical measure of how “surprising” each word choice is, given what came before. Writers who use predictable, simple vocabulary — because English is their second language, or because they’re writing under exam conditions — produce text that looks “low-perplexity” to the model. AI-generated text is also low-perplexity. The overlap is enormous.
This is directly relevant to the systematic AI detection bias documented against international students at English-speaking universities. As the share of international students at US, UK, and Australian universities continues to grow, the affected population also grows.
A 2025 follow-up analysis confirmed the disparity persists across updated model versions. Neurodivergent students who rely on consistent phrasing patterns are similarly over-represented in false positive populations, though no large-scale study has yet quantified this effect at the same scale as the ESL finding.
| Student Population | False Positive Rate | Sample Size | Study |
|---|---|---|---|
| Chinese TOEFL essay writers | 61.3% | 91 essays | Liang et al., Patterns (2023) |
| US eighth-grade students | 5.1% | 88 essays | Liang et al., Patterns (2023) |
| General verified human essays | 26.4% | 37,874 essays | Large-scale ZeroGPT benchmark |
| Non-native English writers (broad) | ~19% | Multiple studies | GPTZero independent tests |
| Professional non-fiction (human) | 30%+ | Internal audits | Multiple vendor internal reports, 2026 |

Scale of the Problem: How Many Students Are Affected?
The U.S. National Center for Education Statistics (NCES) reports approximately 22.35 million students enrolled in degree-granting postsecondary institutions (2023 data). If each writes an average of just one graded submission per week over a 15-week semester, and if 40% of universities run AI detection on those submissions, the scale of potential false accusations at various FPR levels is:
| False Positive Rate | Wrongly Flagged Submissions (US, per semester) | Based On |
|---|---|---|
| 0.24% (GPTZero claim) | ~322,000 | Vendor claimed benchmark |
| 1% (optimistic independent) | ~1.34M | Bloomberg test mid-range |
| 4% (Turnitin CPO admitted) | ~5.36M | Turnitin Chief Product Officer statement |
| 16% (ZeroGPT Pangram test) | ~21.5M | Pangram Labs independent benchmark |
A documented real-world case: Turnitin flagged more than 90% of a Johns Hopkins student’s paper as AI-generated. The professor confirmed after reviewing drafts and materials that it was entirely the student’s own work. Academic misconduct investigations triggered by AI flags have proliferated since 2023, with student appeal rates at institutions with transparent reporting running 15–30% of all AI-flagged cases.
For individual universities, the numbers are easier to visualize. Ohio State University (66,901 enrolled students) at a 4% FPR would see approximately 2,676 students wrongly accused per semester if all submissions were run through detection. The academic misconduct consequences — ranging from grade penalties to expulsion — make this a profound civil liberties issue.
Why Detectors Generate False Positives
The core challenge is that the features most predictive of AI text — low perplexity (predictable word choices), low burstiness (consistent sentence length), and high coherence — are also features of:
- ESL writing, which uses simpler vocabulary by necessity
- Highly-templated academic writing genres (lab reports, legal briefs, executive summaries)
- Neurodivergent writing patterns that rely on consistent phrasing
- Text written under time pressure, which reduces lexical diversity
- Well-edited professional prose, which removes burstiness deliberately
This structural overlap explains why the Turnitin false positive problem is not solved by model updates. A 2024 paper in The Serials Librarian (Tandfonline, doi:10.1080/0361526X.2024.2433256) documented how scholarly librarians and academic writers — whose prose is highly polished and formulaic — face elevated false positive rates even when the content is entirely human-written.
There is also a detection-evasion arms race effect. As AI humanizer tools become more sophisticated, detectors update their models to catch humanized AI text. But these updates often shift the decision boundary in ways that increase FPR for legitimate writing that superficially resembles humanized AI output.
🧮 False Positive Impact Calculator
Estimate how many students at your institution may be wrongly flagged each semester.
What Reduces False Positive Rates?
Liang et al. (2023) showed that using ChatGPT to enhance the vocabulary of TOEFL essays — making them resemble native-speaker writing more closely — reduced the mean false positive rate from 61.3% to 11.6%, a 49.7% reduction. This finding has uncomfortable implications: the standard recommendation for ESL students to write more naturally to avoid detection is backwards. Ironically, using AI to improve the quality of human writing reduces the probability of being falsely flagged for AI use.
For institutions, the most impactful changes are policy-level. Several universities have banned sole reliance on AI detectors, requiring that detection scores be corroborated by conversation with the student, review of drafts, or examination under supervised conditions before any misconduct proceedings are initiated.
For students, documenting your writing process is the most reliable defense. Google Docs and Word version history showing incremental drafting over time is accepted as corroborating evidence at most institutions with formal AI integrity policies.
| Intervention | FPR Reduction | Evidence Level | Notes |
|---|---|---|---|
| Switch from ZeroGPT to Pangram | Up to 26% | Moderate (independent benchmarks) | Requires institutional procurement change |
| Set detection threshold above 20% | Eliminates low-confidence flags | Strong (Turnitin documentation) | Turnitin’s own docs state <20% should not be primary evidence |
| Require human review before proceeding | N/A (policy) | Strong (academic integrity experts) | Widely recommended; most disputes resolved at review stage |
| ESL vocabulary enrichment (pre-submission) | 49.7% (61.3%→11.6%) | Strong (peer-reviewed, PMC10382961) | Perversely, using AI to improve writing reduces AI detection risk |
| Accept incremental draft history as evidence | N/A (policy) | Strong | Google Docs, Word version history accepted at most institutions |
It is worth noting that supervised in-class writing still gets flagged as AI by Turnitin and other tools in documented cases. This directly contradicts the assumption that authentic real-time writing is immune to false positives. The implication is that even requiring in-person writing does not fully protect students from incorrect AI detection scores.
Methodology
This report aggregates data from peer-reviewed research (Liang et al., 2023; Serials Librarian, 2024), independent benchmarks (Pangram Labs, GPTZero’s own benchmarking documentation, Originality.ai meta-analysis), journalism (Washington Post, The Markup), and vendor public disclosures. Where multiple sources report conflicting figures for the same tool, we present the range and note the source of each figure. FPR numbers are not directly comparable across studies due to differing test corpora, evaluation methodologies, and writing genres. All figures should be treated as directionally accurate rather than precise point estimates. We do not accept payment or affiliate compensation for tool rankings; see our independent review methodology.
Frequently Asked Questions
What is a false positive in AI detection?
Which AI detector has the lowest false positive rate?
Why does Turnitin flag real student work as AI?
Are non-native English speakers disproportionately flagged by AI detectors?
How do I defend myself against a false positive AI detection flag?
Should universities rely solely on AI detection tools for academic integrity decisions?
Sources & References
- Liang, W. et al. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7). pmc.ncbi.nlm.nih.gov/articles/PMC10382961/
- Stanford HAI. AI-Detectors Biased Against Non-Native English Writers. hai.stanford.edu
- Pangram Labs. All About False Positives in AI Detectors. pangram.com
- The Markup (2023). AI Detection Tools Falsely Accuse International Students of Cheating. themarkup.org
- Turnitin AI Writing Detection Model Documentation. guides.turnitin.com
- K-12 Dive. Turnitin admits some cases of higher false positives. k12dive.com
- Originality.ai. AI Detection Accuracy Studies: Meta-Analysis of 14 Studies. originality.ai
- GPTZero. How AI Detection Benchmarking Works. gptzero.me
- Academicjobs.com. What AI Detector Do Colleges Use? 2026. academicjobs.com
- Tandfonline (2024). The Problem with False Positives: AI Detection Unfairly Accuses Scholars of AI Plagiarism. doi:10.1080/0361526X.2024.2433256