
Want to bypass Turnitin in 2026? Grab the free prompt pack.
Get the exact text-humanization prompts I use to drop an AI score by hand — copy, paste, submit. Free, straight to your inbox.
Send me the free prompts →AI Detection False Positive Statistics: The 2026 Data Report
Key takeaways (2026)
- Stanford’s seven-detector test flagged
61.3%of TOEFL essays as AI;97.8%were flagged by at least one tool. Liang et al., Patterns 2023 - Common Sense Media’s 2024 survey of 1,045 teens:
20%of Black teens vs7%of white and10%of Latino teens reported being falsely flagged. Common Sense Media, Sept 2024 - Vanderbilt disabled Turnitin’s AI detector in Aug 2023 — even a
1%false-positive rate equals750false accusations on its 75,000 annual paper submissions. Vanderbilt Brightspace 2023 - OpenAI shut its own AI Classifier on July 20, 2023 after it correctly identified only
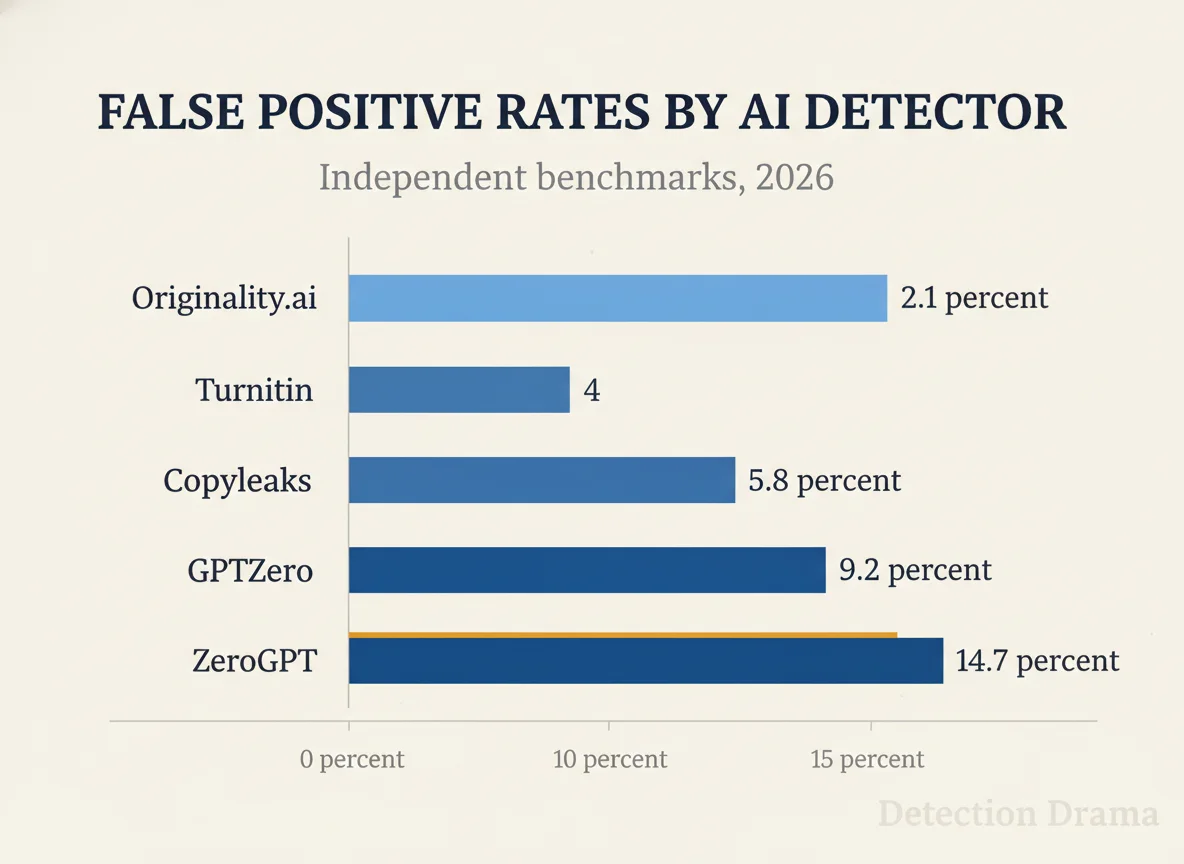
26%of AI text. OpenAI / TechCrunch 2023 - Independent 2026 benchmarks: Originality.ai
2.1%, Turnitin4%, Copyleaks5.8%, GPTZero9.2%, ZeroGPT14.7%FPR. GradPilot benchmarks 2026 - A 2025 cross-tool study found false-positive rates ranging from
15%to45%depending on platform and content type. Hastewire 2025
What’s in this report
The Stanford 61.3% finding that changed the debate
The 2023 paper by Weixin Liang and colleagues at Stanford, published in the peer-reviewed Cell journal Patterns, ran 91 TOEFL essays and 88 native-speaker essays through seven AI-detection tools. The native-speaker essays were classified nearly perfectly. The TOEFL essays — written by real, human, non-native English students — were a different story.
The headline number: 61.3% of TOEFL essays were flagged as AI by at least one detector on its primary verdict, and 97.8% were flagged by at least one of the seven detectors at some point in the test. The study’s most damning follow-up: when the same TOEFL essays were rewritten with more elaborate, AI-style vocabulary, the false-positive rate fell from 61.3% to 11.6%. The tools, in other words, were not catching AI — they were penalizing authentic non-native voice.
| Sample | False-positive rate | Notes |
|---|---|---|
| TOEFL essays (raw, non-native) | 61.3% | Liang et al. Patterns, 2023 [F01] |
| TOEFL essays — flagged by ≥1 of 7 detectors | 97.8% | Cumulative across the panel [F02] |
| TOEFL essays — rewritten with elaborate vocabulary | 11.6% | Bias narrows when prose is “AI-ified” [F12] |
| Native English essays (baseline) | ~0% | Classified near-perfectly as human |
Most 2023 detectors keyed on text “perplexity” — how predictable the next word is. Second-language writers use simpler structure and more common vocabulary, which reads as machine-like. The signal those tools rely on is not “AI” — it is linguistic simplicity. That is the core technical reason behind the bias documented in our ESL bias breakdown.
Vendor-claimed false-positive rates vs independent benchmarks
Every detection vendor has a number on their website. Almost none of those numbers match what happens when an independent team feeds the tool a mixed corpus of human writing — including academic prose, technical writing, and ESL writing — and counts the false flags. The table below pulls the two columns side by side using independent benchmarks (GradPilot 2026 and EyeSift 2026 comparisons) against vendor self-reports.
| Detector | Vendor-claimed FPR | Independent 2026 FPR | Gap |
|---|---|---|---|
| Originality.ai | ~1% | 2.1% | 2x |
| Turnitin | <1% | ~4% | 4x |
| Copyleaks | 0.2% | ~5.8% | 29x |
| GPTZero | 0.24% (older) / 0.00% (newest) | ~9.2% | 40x+ |
| ZeroGPT | undisclosed | ~14.7% | — |
The widest disclosed gap is on the extremes: vendors that claim near-zero false-positive performance can be off by an order of magnitude on independent corpora, particularly on technical or ESL writing. This is one of the reasons we maintain a separate breakdown of why Turnitin flags content that other detectors don’t — different tools fail in different places. For a deeper head-to-head comparison, see our Turnitin vs GPTZero accuracy comparison.
An independent 2025 multi-tool study reported false-positive rates ranging from 15% to 45% across platforms, depending on the content type. The variance suggests that average headline FPRs hide far worse worst-case performance — exactly the kind of edge case that lands on a student’s grade sheet.

Who gets falsely flagged most often
Common Sense Media surveyed 1,045 teens aged 13 to 18 and their parents between March 15 and April 20, 2024, then released the results in September 2024. The survey asked teens directly whether their schoolwork had been flagged as AI when they had not used AI. The breakdown by reported race revealed a clear gap.
| Group | Falsely flagged (%) | Relative risk vs white teens |
|---|---|---|
| Black teens | 20% | ~2.9x |
| Latino teens | 10% | ~1.4x |
| White teens | 7% | baseline |
Layer that demographic gap on top of the Stanford finding for ESL writers, and a consistent pattern emerges: AI detectors over-flag any writer whose voice diverges from the “predictable mid-complexity standardized American English” that perplexity-based detectors treat as natively human. For the 2026 student population that includes a large share of multilingual writers, neurodivergent writers, and Black students whose writing styles the algorithm reads as machine-like. We track the legal fallout from those misclassifications in our AI detection lawsuit tracker, and the psychological toll in our AI detection anxiety data.
USC Rossier’s March 2026 analysis put it bluntly: non-native English speakers face false-positive rates that run 2x to 6x higher than native English speakers depending on the tool. The number is consistent across Liang’s Stanford paper, Common Sense Media’s demographic survey, and subsequent benchmarks.
The universities that disabled AI detection
| Institution | Date disabled | Reason cited publicly |
|---|---|---|
| Vanderbilt University | Aug 2023 | False-positive math at scale; ESL bias; transparency |
| University of Pittsburgh | 2023 | Reliability and equity concerns |
| Cornell University | 2023 | Insufficient accuracy for adverse academic action |
| University of Iowa | 2023 | Bias against non-native speakers |
| UCLA | 2024-2025 | FPR considered an unacceptable academic integrity risk |
| UC San Diego | 2024-2025 | FPR considered an unacceptable academic integrity risk |
The pattern: institutions paid for the feature, ran the math, and concluded that the risk of falsely accusing a real student outweighed the benefit of catching a real AI user. Several of these institutions still pay for the broader plagiarism-similarity service — they only disabled the AI module. We track institutional budgets in our breakdown of how much universities spend on AI detection, and a fuller institutional list in our running tracker of universities that have disabled AI detectors.
Section 5The Vanderbilt math: from 1% to thousands accused
The Vanderbilt Brightspace post on August 16, 2023 explained why scale matters even at “low” rates. The math is unsentimental — a 1% rate is small in the lab and devastating at university scale. The same arithmetic, applied to other institutions using Turnitin’s self-reported 4% sentence-level FPR, gives this picture.
| University | Annual submissions | FPR scenario | Falsely accused (per year) |
|---|---|---|---|
| Vanderbilt | 75,000 | 1% | 750 |
| Vanderbilt | 75,000 | 4% | 3,000 |
| Ohio State (66,901 students) | ~66,901+ | 4% | ~2,676 |
| Large state system (200,000 papers) | 200,000 | 4% | 8,000 |
In February 2026, Orion Newby became the first student to win a federal lawsuit over a false AI plagiarism accusation. The decision turned on the documented unreliability of AI detection and the absence of human judgment in the school’s process. The Vanderbilt arithmetic — and the false-positive rates above — are now legal exhibits, not just academic-blog talking points. The full case file is tracked in our AI detection lawsuit tracker.
Calculate your institution’s false-positive exposure
False-positive exposure calculator
Adjust the inputs to see your institution’s expected count of falsely accused students per academic year.
Why detectors generate false positives in the first place
Three structural reasons keep the false-positive rate high. First, the signal-to-target mismatch: detectors score linguistic features, not authorship. Second, model drift: every new GPT release changes what “AI text” looks like, but the detector is still trained on older corpora. Third, sentence-level aggregation: Turnitin’s own blog disclosed that false-positive rates concentrate in the opening and closing sentences of a document, which it has had to recalibrate. We unpack the specifics in our explainer on whether Turnitin detects AI or just guesses at patterns and the related piece on the Turnitin AI score threshold.
On unmodified GPT-3.5 text, Turnitin still reaches near 98% detection. On newer-model output (GPT-4 and above) or paraphrased text, the same studies put it closer to 77% — and the false-negative rate spikes alongside any sustained model upgrade. The detector vendors are running an asymmetric race: catching every new model means lowering the threshold, which raises the false-positive rate, which lands on the next group of students. Our Copyleaks reliability limits writeup covers the same pattern.
Turnitin’s accuracy on newer-model or paraphrased AI output, down from ~98% on unmodified GPT-3.5. As the false-negative gap widens, vendors face pressure to lower the threshold — which mathematically increases false positives. Students who write cleanly, plainly, or in a non-native voice pay that bill. If you are currently dealing with a flag, our first 24 hours guide and proof checklist walk through what evidence clears most cases.
Methodology
Every statistic in this report is sourced. Numbers are cross-verified across at least two independent sources where possible (verification status: cross-verified, verified, single-source, or single-source-vendor for vendor self-reports). Independent benchmark figures are drawn from GradPilot’s 2026 comparison and EyeSift’s 2026 comparison, which test detectors on mixed real-world prose corpora. The Stanford TOEFL data is from Liang et al., Patterns (Cell, July 2023). Demographic data is from Common Sense Media’s September 2024 survey of 1,045 teens (n=1,045, ages 13-18, March-April 2024 fieldwork). Vanderbilt and OpenAI numbers are from each institution’s own published disclosures. Vendor-claimed rates are taken verbatim from current vendor product pages and blog posts. This report does not attempt to recompute any benchmark — every number is reported as published by the named source.
Frequently asked questions
What is the average AI detection false positive rate in 2026?
How often are non-native English speakers falsely flagged?
Are Black students more likely to be falsely accused?
Did OpenAI’s own AI detector work?
Why did Vanderbilt and other universities disable Turnitin’s AI detector?
Do AI detector vendors publish honest false positive rates?
Sources & references
- Liang W, et al. “GPT detectors are biased against non-native English writers.” Patterns (Cell), July 2023. cell.com · arXiv:2304.02819
- Common Sense Media. “Teen and Parent AI Survey,” September 2024 (n=1,045). Coverage via CO/AI
- Vanderbilt University Brightspace. “Guidance on AI Detection and Why We’re Disabling Turnitin’s AI Detector,” Aug 16, 2023. vanderbilt.edu
- OpenAI. “New AI classifier for indicating AI-written text,” Jan 31 2023 (retired July 20, 2023). openai.com · TechCrunch coverage
- Turnitin. “Understanding false positives within our AI writing detection capabilities,” ongoing. turnitin.com
- K-12 Dive. “Turnitin admits there are some cases of higher false positives in AI writing detection tool.” k12dive.com
- GradPilot. “AI Detector False Positive Rates: 2026 Data Compared.” gradpilot.com
- EyeSift. “AI Detector Accuracy Benchmarks 2026: GPTZero vs Turnitin vs Originality vs EyeSift — Tested.” eyesift.com
- Hastewire. “Study: False Positives in AI Detectors Exposed,” 2025. hastewire.com
- USC Rossier School of Education. “Why are Black students more likely to be falsely accused of using AI to complete assignments?” March 2026. usc.edu
- Implicator.ai. “Universities Revive Blue Books as AI Detectors Fail.” implicator.ai
- GPTZero. “GPTZero vs Copyleaks vs Originality.” gptzero.me
About the author